

在區塊鏈的世界中,總括而言分別有公有鏈、聯盟鏈、私有鏈三種類型,早前的文章亦介紹了很多關於公有鏈(比特幣區塊鏈、以太坊區塊鏈)的資料,當中也經常提到聯盟鏈和私有鏈,但聯盟鏈和私有鏈對於大家來說,卻是比較陌生,可能只知識有這種類型,而對當中的細節可能不太了解。
在公有鏈上,所有節點都透過共識機制共同維護著"同一個"賬本,這個賬本記錄著所有Transaction(交易),為了在所有互不認識的節點之間達成維護賬本的一致性及安全,捨棄了交易效率,導致效率低下(目前比特幣區塊鏈中,每秒只有7筆交易),這是優點也是缺點,同時亦存在匿名公開化的問題,並非完全具有私密性。
在商業世界上,每筆數據或交易的處理效率、私密性是相當重要,所以企業很難將與企業之間的業務放在公有鏈上,正因如此,也是為何會出現有公有鏈、聯盟鏈、私有鏈三種類型的區塊鏈。而聯盟鏈則會較適用於企業間(聯盟)內部進行商業往來的方式,就好比互聯網的和公司局域網,各有其各自的用法和優缺點。

超級賬本
過去由 IBM 帶頭聯同 Intel及 Cisco等巨頭發起的一個聯盟鏈項目-Hyperledger(超級賬本),整個項目由2015年底轉移給 Linux 基金會托管,成為開源項目。Hyperledger 項目中有 5 個子項目,其中,Fabric 是當中最有名的一個,一般而言,大家常說的Hyperledger(超級賬本),實質上指的就是 Fabric。

Hyperledger Fabric
Hyperledger Fabric 是一個企業區塊鏈框架,主要為採用模塊化架構的區塊鏈應用及解決方案提供開發基礎,追求模塊化(Modular)、擴展化(Scalable)、安全化(Secure)。Hyperledger Fabric 可以令共識機制(Consensus)、會員服務(Membership Services)等"組件"可被即插即用(Plug-and-Play)。而在 Hyperledger Fabric 中的智能合約則可以透過"Chaincode"實現。
接下來就深入看看 Hyperledger Fabric 的架構。
Hyperledger Fabric 架構
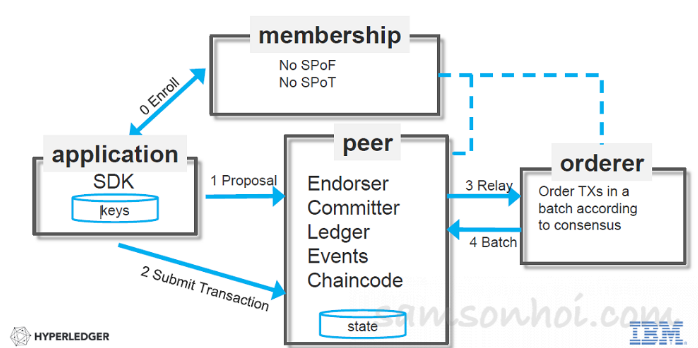
Fabric 1.0 ,將 Peer 節點按功能進行分解為 Endorser, Committer, Ledger, Events, Chaincode,同時把共識機制從節點中抽取出來,獨立成為 Orderer 節點提供即插即用的共識機制,而且加入了多通道(Multi-Channel)功能,可實現了多業務隔離。
多通道(Multi-Channel)
Hyperledger Fabric 中的鏈(Chain)包含了鏈碼(Chaincode)、賬本(ledger)、通道(Channel)的邏輯結構,它將參與方(Organization)、交易(Transaction)進行隔離,滿足了不同業務場景不同的人訪問不同數據的基本要求。通常我們說的多鏈在運維層次上也就是多通道。一個 Peer 節點可以接入多條通道,從而加入到多條鏈,參與到不同的業務中。
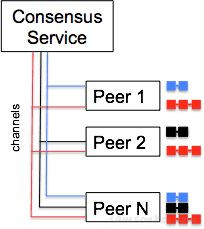
圖中(P1、P2)、(P1、P2、PN)、(P2、P3)組成了三個相互獨立的鏈,Peer 節點只需維護自己加入的鏈的賬本信息,不會感知到其他鏈的存在。這種模式與現實業務場景有諸多相似之處,不同業務有不同的參與方,不參與該業務,也不應該看到業務相關的任何信息。
多通道特性是 Fabric 在商用區塊鏈領域推出的殺手鐧,當然也不完美,雖然 Peer 節點不能看到不相關通道的交易,但是對於 orderer 節點來說,還是所有通道的交易都可以看到,雖然可以使用技術手段分區,但無疑增加了複雜度。
賬本結構
賬本是一系列有序的、不可篡改的狀態轉移記錄日誌。狀態轉移是鏈碼(Chaincode)執行交易(Transaction)的結果,每個交易都是通過增刪改操作提交一系列鍵值對到賬本。一系列有序的交易被打包成塊,這樣就將賬本串聯成了區塊鏈。同時,一個狀態數據庫維護賬本當前的狀態,因此也被叫做世界狀態。在 Fabric 1.0 中,每個通道都有其賬本,每個 Peer 節點都保存著其加入的通道的賬本,包含著交易日誌(賬本數據庫)、狀態數據庫以及歷史數據庫。
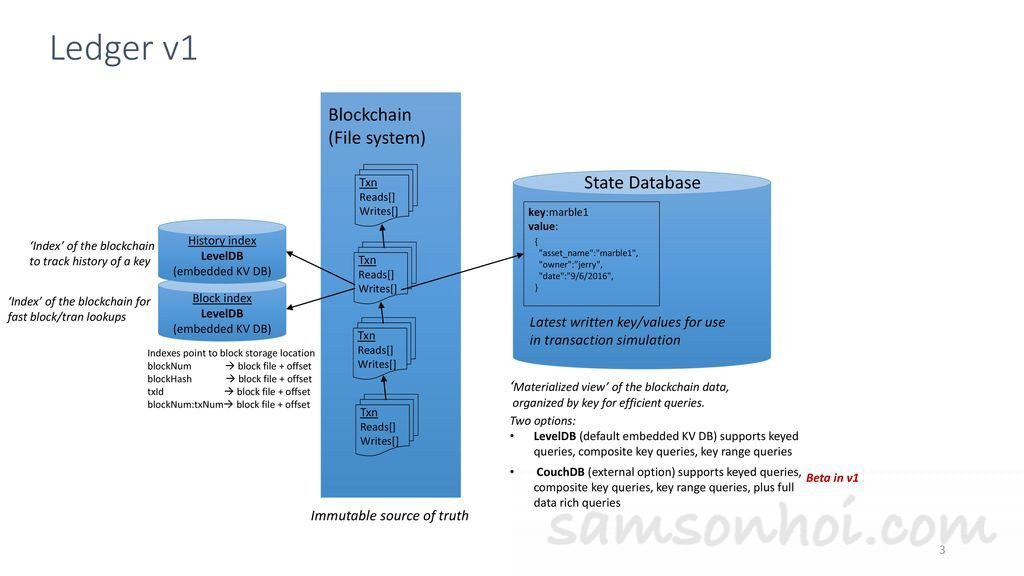 賬本狀態數據庫實際上存儲的是所有曾經在交易中出現的鍵值對的最新值。調用鏈碼執行交易可以改變狀態數據,為了高效的執行鏈碼調用,所有數據的最新值都被存放在狀態數據庫中。就邏輯上來說,狀態數據庫僅僅是有序交易日誌的快照,因此在任何時候都可以根據交易日誌重新生成。狀態數據庫會在 Peer 節點啟動的時候自動恢復或重構,未完備前,該節點不會接受新的交易。狀態數據庫可以使用LevelDB 或者CouchDB。LevelDB 是默認的內置的數據庫,CouchDB 是額外的第三方數據庫。跟LevelDB 一樣,CouchDB 也能夠存儲任意的二進制數據,而且作為JSON 文件數據庫,CouchDB 額外的支撐JSON 富文本查詢,如果鏈碼的鍵值對存儲的是JSON,那麼可以很好的利用CouchDB 的富文本查詢功能。
賬本狀態數據庫實際上存儲的是所有曾經在交易中出現的鍵值對的最新值。調用鏈碼執行交易可以改變狀態數據,為了高效的執行鏈碼調用,所有數據的最新值都被存放在狀態數據庫中。就邏輯上來說,狀態數據庫僅僅是有序交易日誌的快照,因此在任何時候都可以根據交易日誌重新生成。狀態數據庫會在 Peer 節點啟動的時候自動恢復或重構,未完備前,該節點不會接受新的交易。狀態數據庫可以使用LevelDB 或者CouchDB。LevelDB 是默認的內置的數據庫,CouchDB 是額外的第三方數據庫。跟LevelDB 一樣,CouchDB 也能夠存儲任意的二進制數據,而且作為JSON 文件數據庫,CouchDB 額外的支撐JSON 富文本查詢,如果鏈碼的鍵值對存儲的是JSON,那麼可以很好的利用CouchDB 的富文本查詢功能。
Fabric 的賬本結構中還有一個可選的歷史狀態數據庫,用於查詢某個 key 的歷史修改記錄,需要注意的是,歷史數據庫並不存儲key 具體的值,而只記錄在某個區塊的某個交易裡,某 key 變動了一次。後續需要查詢的時候,根據變動歷史去查詢實際變動的值,這樣的做法減少了數據的存儲,當然也增加了查詢邏輯的複雜度,各有利弊。
賬本數據庫是基於文件系統,將區塊存儲於文件塊中,然後在LevelDB 中存儲區塊交易對應的文件塊及其偏移,也就是將LevelDB 作為賬本數據庫的索引。文件形式的區塊存儲方式如果沒有快速定位的索引,那麼查詢區塊交易信息可能是噩夢。現階段支持的索引有:
- 區塊編號
- 區塊哈希
- 交易ID 索引交易
- 區塊交易編號
- 交易ID 索引區塊
- 交易ID 索引交易驗證碼
鏈碼 Chaincode
Fabric 架構更多的是針對Fabric 平台運維工程師,而對更多的應用開發者來說,鏈碼其實才是最重要的。鏈碼(Chaincode)是Hyperledger Fabric 提供的智能合約,是上層應用與底層區塊鏈平台交互的媒介。現階段,Fabric 提供Go、Java 等語言編寫的鏈碼。所有的鏈碼都繼承兩個接口,init 和invoke。init 接口用於初始化合約,在整個鏈碼的生命週期裡,該接口僅僅執行一次。剩下的invoke 接口是編寫業務邏輯的唯一入口,雖然只有一個入口,但是可以根據參數傳遞的不同自由區分不同業務邏輯,靈活性很高。比如應用開發者規定Invoke 接口的第一個參數是合約方法名,剩餘的Invoke 參數列表是傳遞給該方法的參數,那麼就可以在Invoke 接口方法體中根據方法名的不同分流不同業務了。
那麼在合約裡能夠獲取哪些內容呢?合約接口能獲得數據分為三類:
- 輸入參數獲取
- 這點很好理解,我們只有知道此次調用的輸入,才能處理邏輯,推導輸出;
- 與狀態數據庫和歷史數據庫交互
- 在合約層,我們可以將區塊鏈底層當做是一個鍵值對數據庫,合約就是對數據庫中鍵值的增刪改查;
- 與其他合約的交互
- 在合約執行的過程中,可以與其他合約交換數據,做到類似跨鏈的效果。有了這種形式的數據獲取方式,其實就可以將聯繫不緊密的業務邏輯拆分為多個合約,只在必要的時候跨合約調用,非常類似於現在提倡的微服務架構。
編寫鏈碼還有一個非常重要的原則:不要出現任何本地化和隨機邏輯。此處的本地化,不是指語言本地化,而是執行環境本地化。區塊鏈因為是去中心架構,業務邏輯不是只在某一個節點執行,而是在所有的共識節點都執行,如果鏈碼輸出與本地化數據相關,那麼可能會導致結果差異,從而不能達成共識。比如,時間戳,隨機函數等。這些方法是鏈碼編程的禁地,除非你知道你的用意,否則慎用!
節點 Peer、通道 Channel 和鏈碼 Chaincode 之間的關係
節點 Peer 是一個獨立存在的計算機節點,不管是物理機還是虛擬機,總之是獨立實體。在 Peer 沒有加入任何通道之前,是不能夠做任何業務的,因為沒有業務載體。
通道 Channel 就是業務載體,是純粹的邏輯概念。
鏈碼 Chaincode 就是業務,業務是跑在通道裡的,不同的通道即便是運行相同的鏈碼,因為載體不同,可認為是兩個不同業務。
三者需要互相配合才能構成一個完整的 Hyperledger Fabric 區塊鏈。
簡單例子:每個人的手機就是一個 Peer,手機的APP應用就好比 Chaincode,打開APP應用連接到APP 應用的伺服器就好比建立了一條通道。
代幣 Token
在公有鏈上,存在激勵機制,通過獎勵為交易打包(挖礦)的"礦工"達成共識機制,給予獎勵代幣,維持區塊鏈網絡的正常運作。
在 Hyperledger Fabric 這種聯盟鏈上,由於都是信任的節點,並不一定要透過挖礦這種方式達成共識,因此也未必需要代幣 Token。如一定要使用代幣,可以透過鏈碼 Chaincode 進行實現。
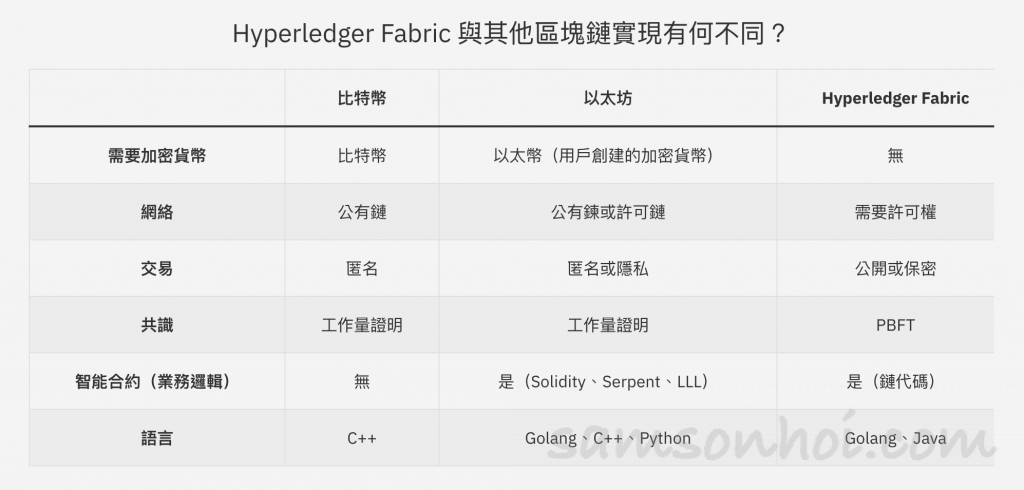
與其他區塊鏈的異同
參考文獻
Hyperledger Fabric - Hyperledger Projects
一文理解超級賬本Hyperledger Fabric的架構與坑