


在區塊鏈的共識機制中,適用於聯盟鏈(許可鏈)及私有鏈的主要有PBFT、Raft、Paxos。
上一篇已提及過 拜占庭容錯 PBFT 《區塊鏈 Blockchain – 共識機制之實用拜占庭容錯 PBFT》,今次就理解一下 Raft。
歷史
Raft 的出現很大程度是基於 Paxos 算法難以理解和實現。
1990年,Leslie Lamport (還記得早前我在上一篇文章講述共識機制 PBFT 中提及過的作者 Leslie Lamport 嗎?沒錯,也是他)提出了一種基於消息傳遞的一致性算法-Paxos,但由於當時大家都難以理解這個算法的思想和在實際中難以實現,所以大家都沒太大興趣。
1998年,Leslie Lamport 將這個算法在ACM上正式發表,同樣因為太難理解和實現,亦沒有得到重視,隨後,作者有見及此,換了一個角度重新發表一篇論文《Paxos Made Simple》,大家才開始逐漸理解 Paxos 算法,但 Paxos 仍屬於一種"理論",距離實現還需要基於 Paxos 做一些擴展才能在實際中應用。
就正因為 Paxos 的難以理解和實現,導致了後來 Raft 的出現。
2013年,兩位 Stanford University 的教授發表了一篇題為《In search of an Understandable Consensus Algorithm (Extended Version)》(尋找一種易於理解的一致性算法),這被認為是一種簡易版的Paxos,性能和功能都與 Paxos 一樣,同時易於理解和實現,這就是 Raft 出現的原因。
定義(概念)
Raft 是用於實現分散式系統的一種容易理解的共識機制,主要用來管理日誌複製的一致性。
Raft 的核心思想很簡單:
如果在分散式系統中多個數據庫的初始狀態一致,只要之後進行的操作順序一致,就能保證之後的執行結果一致。
試想像一下,假設把三個數據庫想像成是你面前的三本賬本,只要每次在第一本賬本上寫上了一筆記錄時,同時將這筆記錄同樣地寫在另外兩本賬本上,那麼這三本賬本的數據始終是一樣的。
Raft 取代複雜難懂的Paxos算法,並且證明可以提供與Paxos相同的容錯性以及性能,並且更容易應用到實際系統中。
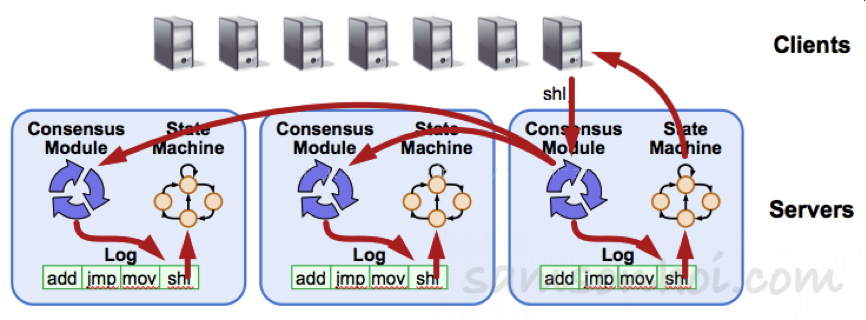
Raft 集群中,伺服器的三種角色
而在一個 Raft 集群(Raft cluster)中,至少包含 5 個伺服器,允許系統有 2 個故障伺服器,在系統初始時,每個伺服器都處於追隨者的狀態。而每個伺服器將會是這三種角色其中一個:
領袖(Leader):正常狀態下只有一個領袖 ,其他都是追隨者,它會負責處理所有來自外部 Client 的請求及進行日誌複製(日誌複製是單向的,即領袖發送給追隨者),先就是負責"出塊"的節點。
候選人(Candidate):由追隨者向領袖轉換的中間狀態,等待被選舉為領袖。
追隨者(Follower):它是被動的節點,對來自 Client 和候選人的請求做出響應。如果收到外部 Client 的請求,就會將請求會被轉發給領袖。
而這三種角色在條件滿足下可以互相轉換,而在正常情況下只會有一個領袖,其他都是追隨者。而領袖會負責所有外部的請求。
Raft 內三個重要概念
- Replicated State Machine 狀態複製機
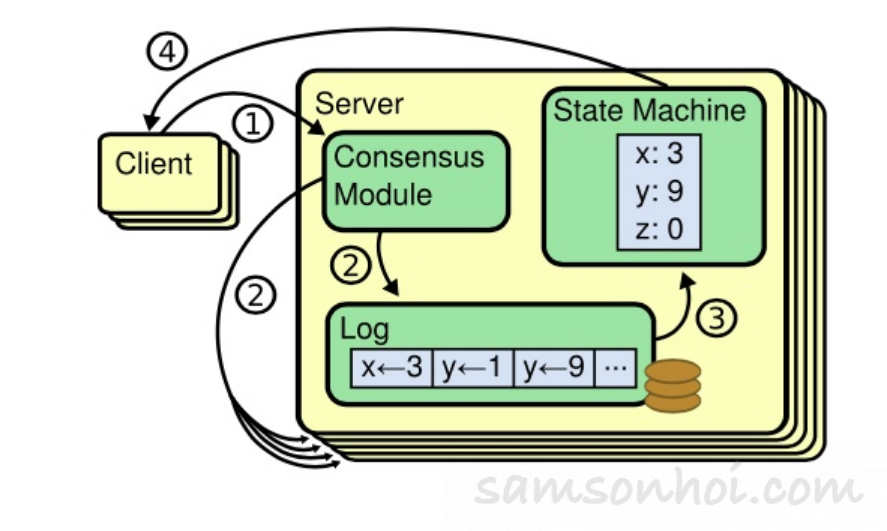
Raft 一個節點上,
(1)一致性模組(Consensus Module,也就是分散式共識機制)接收到了來自 Client 的命令;
(2)把接收到的命令寫入到日誌中,該節點和其他節點通過一致性模塊進行通信確保每個日誌最終包含相同的命令序列;
(3)一旦這些日誌的命令被正確複製,每個節點的狀態機(State Machine)都會按照相同的序列去執行他們,從而最終得到一致的狀態,再將達成共識的結果返回給 Client。
處理過程大致如下:
2. Term 任期
在分散式系統中,由於每個節點之間可能會由於自身設置、地理環境的不同而導致該節點的時鐘並不一致,各節點為了識別"過期"的信息,一致同步的時間戳就顯得相當重要了。
Raft 採用了 Term 任期 的概念,將時間邏輯分段,就像這樣
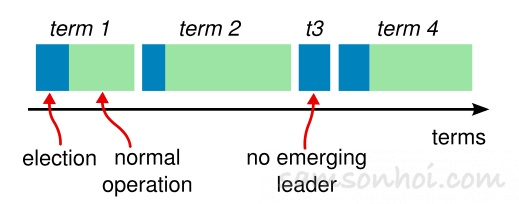
解釋一下,每個任期開始時,都是一次領袖選舉(Leader Election),一個或多個候選人(Candidate)會嘗試成為領袖(Leader)。如果一個人贏得選舉,就會在該任期(Term)內剩餘的時間擔任領袖,負責"出塊"。在某些情況下,選票可能會被評分,有可能沒有選出領袖(例如t3),那麼,將會開始另一任期,並且立即開始下一次選舉。
Raft 算法保證在給定的一個任期最少要有一個領袖。那麼,是如何保證的呢?
3. 心跳(Heartbeat)和選舉超時機制(Election Timeout)
Raft 算法中,設有 心跳(Heartbeat)和選舉超時(Election Timeout)互相配合控制領袖選舉,以保證在給定的一個任期內最少會有一個領袖。
心跳(Heartbeat)一旦選出了領袖節點之後,這個節點會向其他所有節點發送空的AppendEntries RPC(即 心跳 HeartBeat),而其他節點收到後,角色就會由變為追隨者,同時重置選舉定時器,而領袖節點在空閒的時間內會重複發送以防止選舉超時。
選舉超時(Election Timeout)如果追隨者的節點在150ms~300ms(在這範圍內隨機設定)內沒有收到領袖的心跳 RPC,就會認為領袖節點失效,隨即展開新一輪選舉,選出新的領袖。
運作流程
為了更好地瞭解 Raft 這個共識機制,個人強烈建議先把這段動畫解說完整看一下,簡單清晰,容易理解。
Raft 將 Paxos 概念簡化,並將複雜概念分解成三個子過程,令人更容易了解:
1. 領袖選舉(Leader Election)
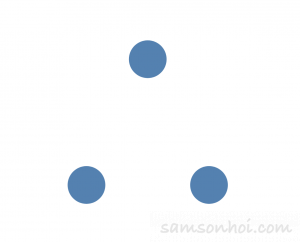
開始時,所有節點都是以追隨者的角色啟動,同時啟動選舉計時器(150ms~300ms 時間隨機,降低衝突機率);

如果當一個節點(左下)發現選舉定時器超時,一直都沒有收到來自領袖節點的心跳 RPC,則該節點就會成為候選人,並且一直處於該狀態,直至下面三種情況發生:
- 該候選人節點嬴得選舉;
- 其他節點嬴得選舉;
- 在一段時間後沒有任何一個節點嬴得選舉(隨即進入下一輪的選舉,並隨機設置選舉定時器時間);
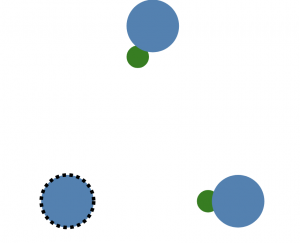
同時,這個節點成為候選人後,就會向其他節點發送投票請求(Request Vote),如果得過半數以上節點的同意,就會成為領袖 Leader 節點;但如果仍未選出領袖,則進入下一個任期,重新選舉。
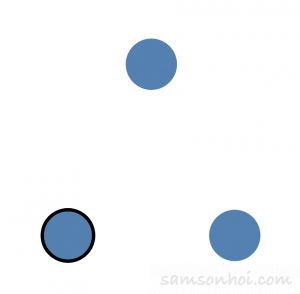
完成選舉後,這個領袖節點就會定時向其他節點發送心跳 RPC,即向他們表示"我仍然正常運行",同時重置這些節點的選舉定時器;
2.日誌複製(Log Replication)
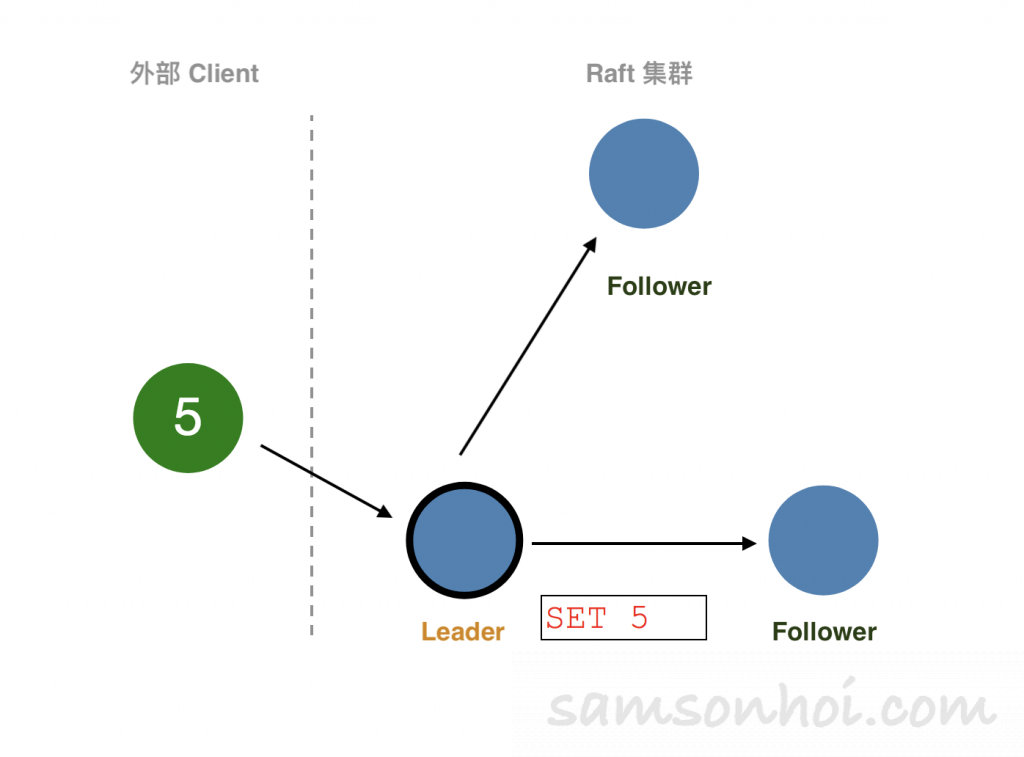
外部的 Client 向 Leader 提交指令(SET 5),Leader 收到命令後,將命令追加到本地日誌中。此時,這個命令處於"uncommitted" 狀態,複製狀態機不會執行該命令。
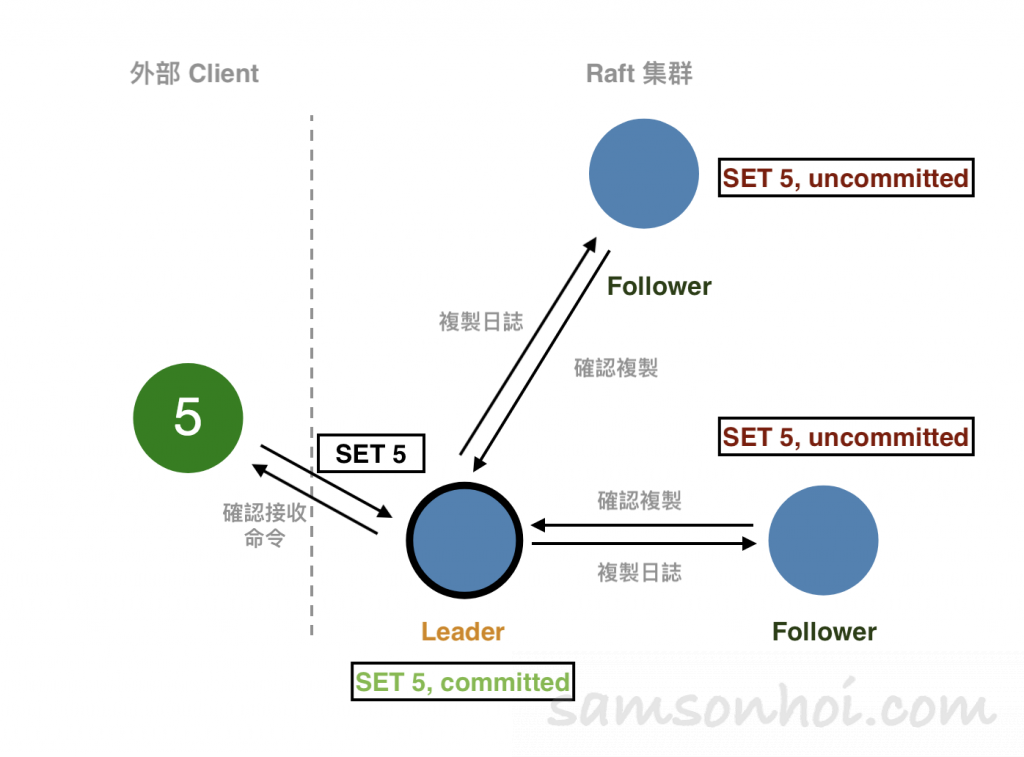
然後,Leader將命令(SET 5)併發複製給其他節點,並等待其他其他節點將命令寫入到日誌中,如果此時有些節點失敗或者比較慢,Leader 節點會一直重試,知道所有節點都保存了命令到日誌中。Leader節點就提交命令(即被狀態機執行命令,SET 5),並將結果返回給 Client 。
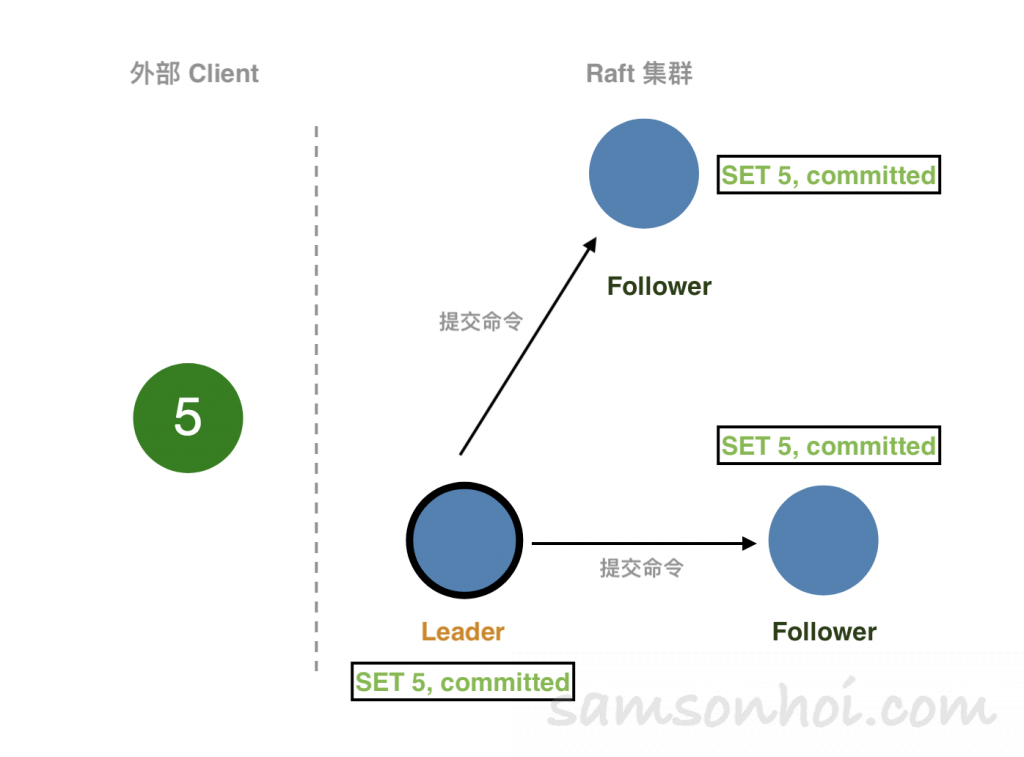
Leader 節點在提交命令後,下一次的心跳 RPC 中就帶有通知其他節點提交命令的消息,其他節點收到 Leader 的消息後,就將命令應用到狀態機中(State Machine),最終每個節點的日誌都保持了一致性。
3.安全性(Safety)
領袖選舉及日誌複製 這兩個部份仍不能保證每一個狀態機能按照相同的順序執行同樣的指令。假設當領袖提交了若干日誌條目的同時一個追隨者可能宕機了(失效),之後它又被選為了領袖,接著用新的日誌條目覆蓋掉了舊的日誌,最後,不同的狀態機可能執行不同的命令序列,導致各節點間的日誌不一致。
而為了解決這個問題,Raft算法通過在領袖選舉階段增加一個限制來完善了Raft算法。這個限制能保證,對於固定任期,任何領袖都擁有之前任期提交的全部日誌命令。Raft算法通過投票的方式來阻止那些沒有包含全部日誌命令的節點贏得選舉。
所以,可理解為
- 日誌的流向只有由領袖到追隨者,並且領袖不能覆蓋日誌;
- 日誌不是最新的,沒有全部日誌的節點不能成為候選人;
而一個候選人節點要嬴得選舉,成為領袖,就必須跟系統中大部份的節點進行通信,意味著候選人的日誌要與大多數節點上的日誌相同。而 Raft 亦提供了 RequestVote RPC 實現這個限制。
RequestVote RPC:候選人在選舉期間發起,RPC中包括候選人的日誌信息,如果它自己的日誌比候選人的日誌要新,那麼它會拒絕候選人的投票請求;
說起 RPC 還有兩種:
AppendEntries RPC:由領袖節點發起的一種心跳 RPC,日誌複製也在該命令中完成。
InstallSnapshot RPC:領袖節點用來發送快照給太落後的追隨者。
然而,怎樣判斷兩個節點中的日誌內容哪個比較新呢?Raft 算法通過比較日誌中最後一個命令的索引(Index)和任期編號(Term)判斷哪一個節點的日誌內容比較新。
如果兩個日誌的任期編號不同,任期編號大的日誌內容較新
如果兩個日誌的任期編號相同,內容長的日誌則被認為較新
如果一個任期內,假設領袖節點突然無法連接網絡,沒有及時發送心跳 RPC給其他追隨者,這些追隨者將會重新選舉一個領袖,繼續領袖的責任,如果後來原來的領袖節點能夠成功連接網絡,它的角色將會變為追隨者,而不是領袖,而且在它在斷開連接的這段時間,它任何的更新都不能確認,都會全部回滾,然後,作為一個追隨者接收新的領袖節點的更新,不斷重複。
目前市場上的應用

熱門的 Hyperledger Fabric 超級賬本、國內開源的 FISCO BCOS 中等的區塊鏈系統中,Raft, PBFT等一些共識機制被設計成可插拔的模組。
![]()
而 ETCD 則是將 Raft 算法實作成一個 Library,可以讓其他應用快速地應用 Raft 算法,它的目標是構建一個高可用的分散式鍵值(Key-Value)數據庫。
優缺點
優點
1.易於理解,容易實現
Paxos 算法難以理解,Raft 將整個算法清楚分成兩部份,並利用日誌的連續性做了簡化,從本質上來說,流程及描述清晰,比起Paxos 來說更容易實現和理解。
2. 簡化 Paxos,效率相同
Raft 就相當於 Multi-Paxos,而且和 Paxos 算法一樣高效,Raft 將 Leader 選舉、日誌複製、安全性等關鍵元素分離,並採用更強的一致性以減少必須考慮狀態的數量。
缺點
1. Raft 只適用聯盟鏈(許可鏈)或私有鏈
2. 無法進行拜占庭容錯的缺陷
總結
Raft 共識機制相對於 Paxos 來說,卻是在概念上簡化了不少,將集群中 Leader 角色的地位強化了,而且流程和描述清晰,令大家更容易理解和實現,而且在安全性及效率可以與 Paxos 相同,目前也作為市場上大部份聯盟鏈(許可鏈)平台可選的共識機制之一,但缺陷卻是去中心化較弱,只適用於聯盟鏈(許可鏈)或私有鏈 ,不過,共識機制就是這樣,沒有一個能適用於所有應用場景的共識機制,需要在去中心化、安全性、出塊效率之間作出取捨,沒有最好,只有最適用。